I am a PhD student at Seoul National University, working in the VIP Lab under the supervision of Prof. Joonseok Lee.
My research focuses on 3D computer vision, particularly Gaussian Splatting and modeling motion in Gaussians (e.g., articulated objects). Currently, I am interested in injecting 3D knowledge into Vision-Language-Action (VLA) models.
Articulated object reconstruction from sparse-view images is an ill-posed problem that requires simultaneous inference of geometry and underlying articulation structure. Existing methods based on NeRF and 3D Gaussian Splatting (3DGS) typically rely on dense views or strong priors (e.g., depth maps, joint types, a predefined number of joints) and require costly per-object optimization. We propose ArtSplat, the first feed-forward framework for articulated 3D Gaussian Splatting, which reconstructs both geometry and joint parameters from sparse multi-view images across multiple articulation states in a single forward pass. To this end we introduce a per-pixel joint map representation that integrates joint parameter estimation into the feed-forward pipeline, and a Cross-State Attention (CSA) mechanism with state tokens that captures discrete motion across input states. Experiments on 68 articulated objects from PartNet-Mobility, covering both single- and multi-joint configurations, demonstrate competitive geometry and joint-estimation performance while running over 400x faster than baselines.
@unpublished{lee2026artsplat,title={{ArtSplat}: Feed-Forward Articulated {3D} {G}aussian {S}platting from Sparse Multi-State Uncalibrated Views},author={Lee, Inseo and Kim, Yoonji and Sohn, Eugene and Lee, Jiwoong and You, Jungmin and Lee, Joonseok and Kim, Jin-Hwa},year={2026},}
GaussianVideo: Efficient Video Representation and Compression by Gaussian Splatting
Inseo Lee, Youngyoon Choi, and Joonseok Lee
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Perception Beyond the Visible Spectrum (PBVS), 2025
We propose GaussianVideo, a video representation and compression method built on 2D Gaussian Splatting with deformable transformations. Compared to neural implicit representation baselines, our approach reduces GPU memory usage by up to 78.4%, achieves 5.5x faster training and 12.5x faster decoding, while maintaining competitive reconstruction quality. The work demonstrates that explicit, primitive-based representations can scale to video and offer practical efficiency advantages over implicit alternatives.
@inproceedings{lee2025gaussianvideo,title={{GaussianVideo}: Efficient Video Representation and Compression by {G}aussian {S}platting},author={Lee, Inseo and Choi, Youngyoon and Lee, Joonseok},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Perception Beyond the Visible Spectrum (PBVS)},year={2025},}
Masked Autoencoder (MAE) is a widely adopted self-supervised approach for visual representation learning. We discover that, even with random masking, MAEs inherently begin to perform pattern-based patch-level clustering very early in pretraining. Building on this observation, we propose a self-guided masking strategy that generates informed masks from the model’s emergent clustering signal, replacing the naive random masking of the vanilla MAE and yielding consistent gains on downstream tasks.
@inproceedings{shin2024selfguided,title={Self-Guided Masked Autoencoder},author={Shin, Jeongwoo and Lee, Inseo and Lee, Junho and Lee, Joonseok},booktitle={Advances in Neural Information Processing Systems (NeurIPS)},year={2024},}

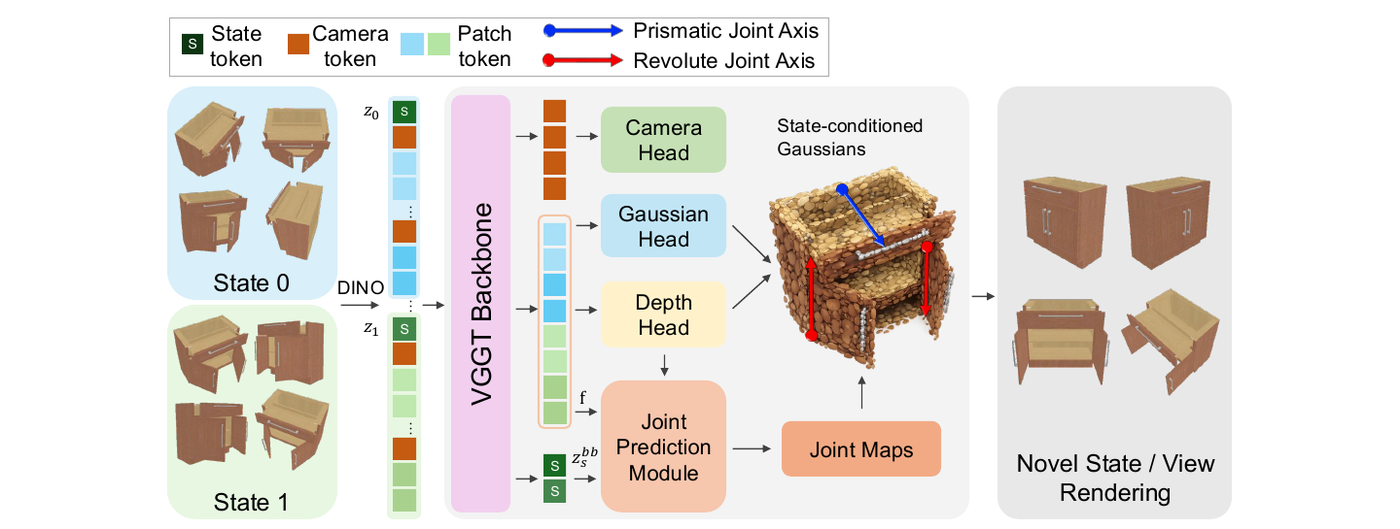 ArtSplat: Feed-Forward Articulated 3D Gaussian Splatting from Sparse Multi-State Uncalibrated Views2026
ArtSplat: Feed-Forward Articulated 3D Gaussian Splatting from Sparse Multi-State Uncalibrated Views2026
